Abstract
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question “Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?”. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence (Seq2Seq) task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture.
Poster
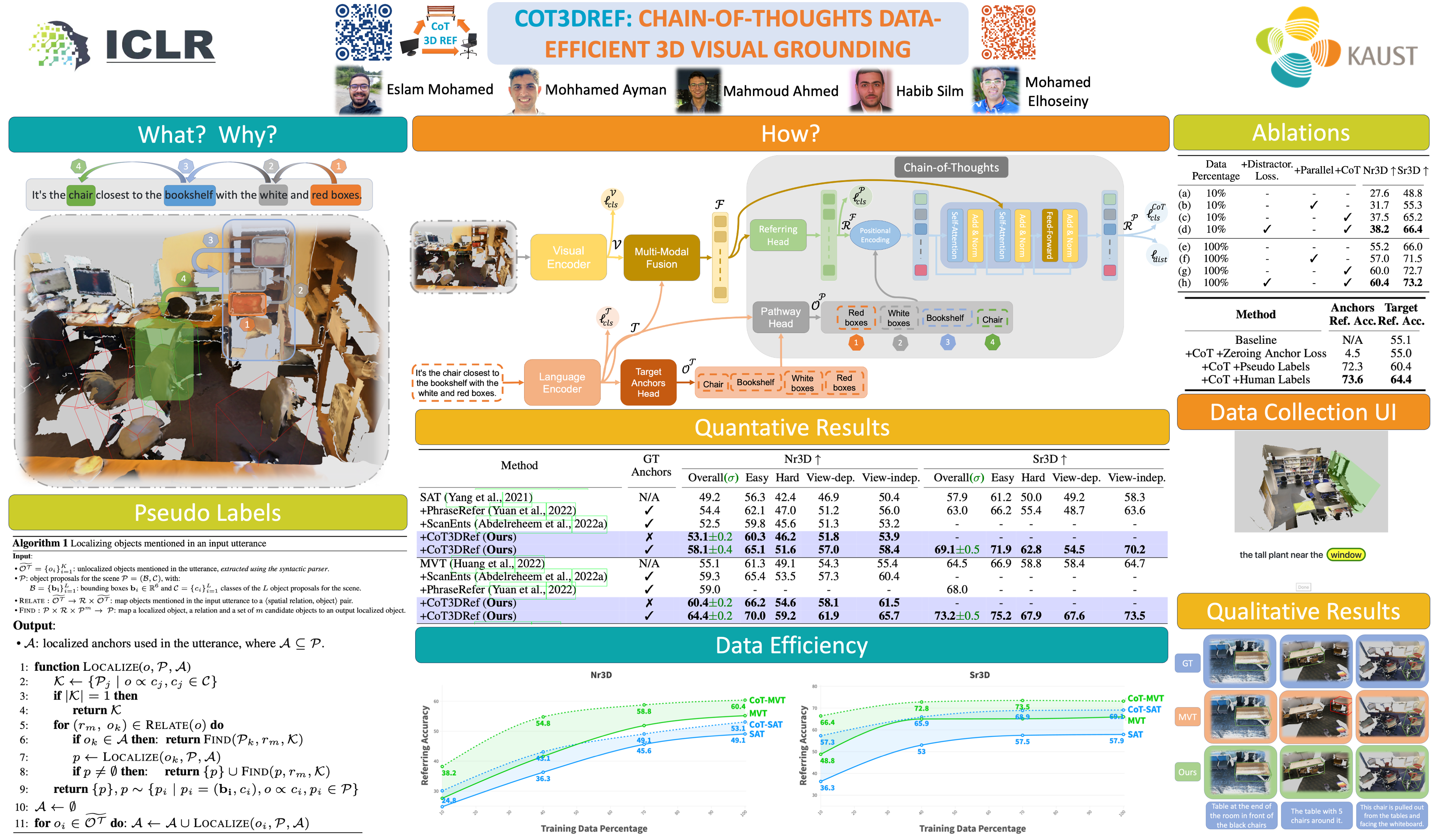
Main Idea
In this paper, we mainly answer the following question: Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system? To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence (Seq2seq) task. The input sequence combines 3D objects from the input scene and an input utterance describing a specific object. On the output side, in contrast to the existing 3D visual grounding architectures, we predict the target object and a chain of anchors in a causal manner. This chain of anchors is based on the logical sequence of steps a human will follow to reach the target.
Architecture
An overview of our Chain-of-Thoughts Data-Efficient 3D visual grounding framework (CoT3DRef). First, we predict the anchors OT from the input utterance, then sort the anchors in a logical order using the Pathway module. Then, we feed the multi-modal features, the parallel localized objects, and the logical path to our Chain-of-Thoughts decoder to localize the referred object and the anchors in a logical order.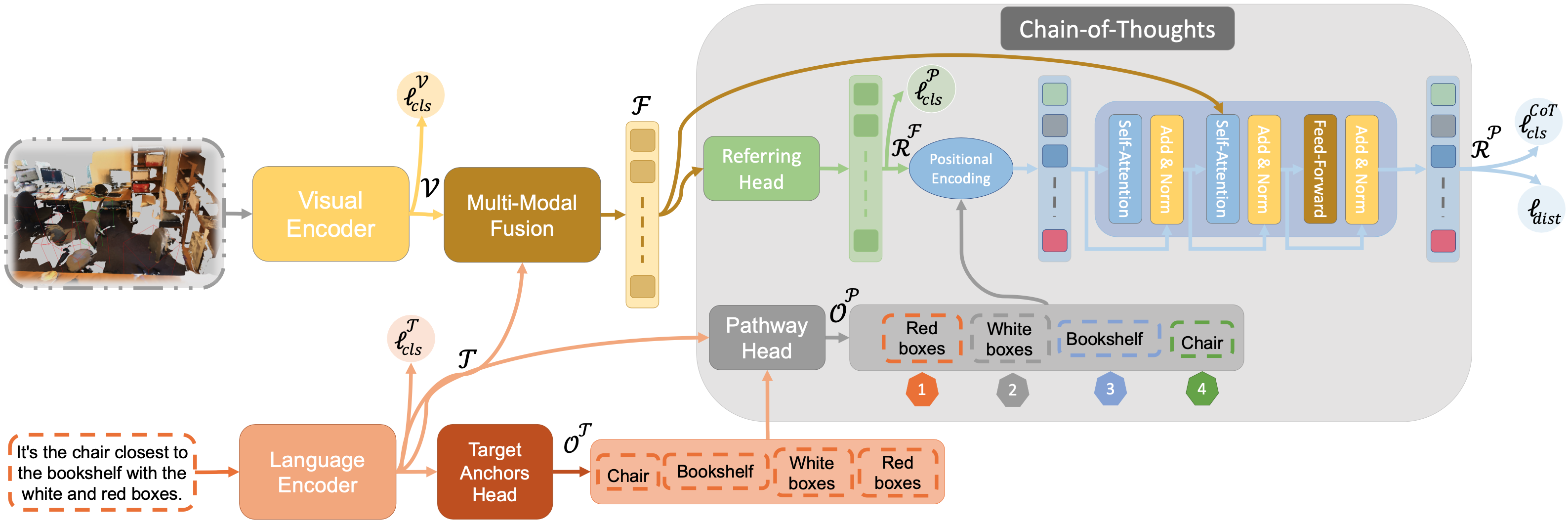
Pseudo Labels
During the training phase, our proposed framework requires more information than the standard available GT in existing datasets. These datasets only annotate the referred object and the target. However, our framework requires anchor annotations. Three types of extra annotations are needed: 1) Given an input utterance, we need to identify the mentioned objects other than the target; the anchors. 2) Once we extract the anchors from the utterance, we need to know their logical order to create a chain of thoughts. 3) Finally, we need the localization information for each anchor, i.e., to assign a bounding box to every anchor. To make our framework self-contained and scalable, we do not require any manual effort. Instead, we collect pseudo-labels automatically without any human intervention.
Data Efficient
We assess our model on a challenging setup, where we assume access to only limited data. Four percentage of data is tested, i.e., 10%, 40%, 70%, and 100%. As shown in Figure 2, on the Sr3D dataset, using only 10% of the data, we match the same performance of MVT and SAT that are trained on 100% of the data. This result highlights the data efficiency of our method. Furthermore, when trained on 10% of the data on Nr3D with noisy pseudo labels, we still surpass all the baselines with considerable margins.
Quantitative Results
By effectively localizing a chain of anchors before the final target, we achieve state-of-the-art results without requiring any additional manual annotations.
Qualitative Results
As shown in the below figure , the first three examples show that our model successfully localizes the referred objects by leveraging the mentioned anchors, such as “the table with 5 chairs around”. However, in the ambiguous description shown in the fourth example: “2nd stool from the left”, the model incorrectly predicts the stool, as it is view-dependent. In other words, if you look at the stools from the other side, our predicted box will be correct. Additionally, the last example shows a challenging scenario where a negation in the description is not properly captured by our model.
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question “Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?”. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence (Seq2Seq) task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture.
Poster
Main Idea
In this paper, we mainly answer the following question: Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system? To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence (Seq2seq) task. The input sequence combines 3D objects from the input scene and an input utterance describing a specific object. On the output side, in contrast to the existing 3D visual grounding architectures, we predict the target object and a chain of anchors in a causal manner. This chain of anchors is based on the logical sequence of steps a human will follow to reach the target.
Architecture
An overview of our Chain-of-Thoughts Data-Efficient 3D visual grounding framework (CoT3DRef). First, we predict the anchors OT from the input utterance, then sort the anchors in a logical order using the Pathway module. Then, we feed the multi-modal features, the parallel localized objects, and the logical path to our Chain-of-Thoughts decoder to localize the referred object and the anchors in a logical order.
Pseudo Labels
During the training phase, our proposed framework requires more information than the standard available GT in existing datasets. These datasets only annotate the referred object and the target. However, our framework requires anchor annotations. Three types of extra annotations are needed: 1) Given an input utterance, we need to identify the mentioned objects other than the target; the anchors. 2) Once we extract the anchors from the utterance, we need to know their logical order to create a chain of thoughts. 3) Finally, we need the localization information for each anchor, i.e., to assign a bounding box to every anchor. To make our framework self-contained and scalable, we do not require any manual effort. Instead, we collect pseudo-labels automatically without any human intervention.
Data Efficient
We assess our model on a challenging setup, where we assume access to only limited data. Four percentage of data is tested, i.e., 10%, 40%, 70%, and 100%. As shown in Figure 2, on the Sr3D dataset, using only 10% of the data, we match the same performance of MVT and SAT that are trained on 100% of the data. This result highlights the data efficiency of our method. Furthermore, when trained on 10% of the data on Nr3D with noisy pseudo labels, we still surpass all the baselines with considerable margins.
Quantitative Results
By effectively localizing a chain of anchors before the final target, we achieve state-of-the-art results without requiring any additional manual annotations.
Qualitative Results
As shown in the below figure , the first three examples show that our model successfully localizes the referred objects by leveraging the mentioned anchors, such as “the table with 5 chairs around”. However, in the ambiguous description shown in the fourth example: “2nd stool from the left”, the model incorrectly predicts the stool, as it is view-dependent. In other words, if you look at the stools from the other side, our predicted box will be correct. Additionally, the last example shows a challenging scenario where a negation in the description is not properly captured by our model.
