How does it work?
Most pre-trained learning systems are known to suffer from bias, which typically emerges from data, the model, or both. Measuring and quantifying bias and its sources is a challenging task and has been extensively studied in image captioning. Despite the significant effort in this direction, we observed that existing metrics lack consistency in the inclusion of the visual signal. In this paper, we introduce a new bias assessment metric, dubbed ImageCaptioner 2 , for image captioning. Instead of measuring the absolute bias in the model or the data, ImageCaptioner 2 pay more attention to the bias introduced by the model w.r.t the data bias termed bias amplification. Unlike the existing methods, which only evaluate the image captioning algorithms based on the gener- ated captions only, ImageCaptioner 2 incorporates the image while measuring the bias. We verify the effectiveness of our ImageCaptioner 2 metric across 11 different image captioning techniques on three different datasets, i.e., MS-COCO caption dataset, Artemis V1, and Artemis V2, and on three different protected attributes, i.e., gender, race, and emotions. In addition, our metric show a significant robustness against LIC.
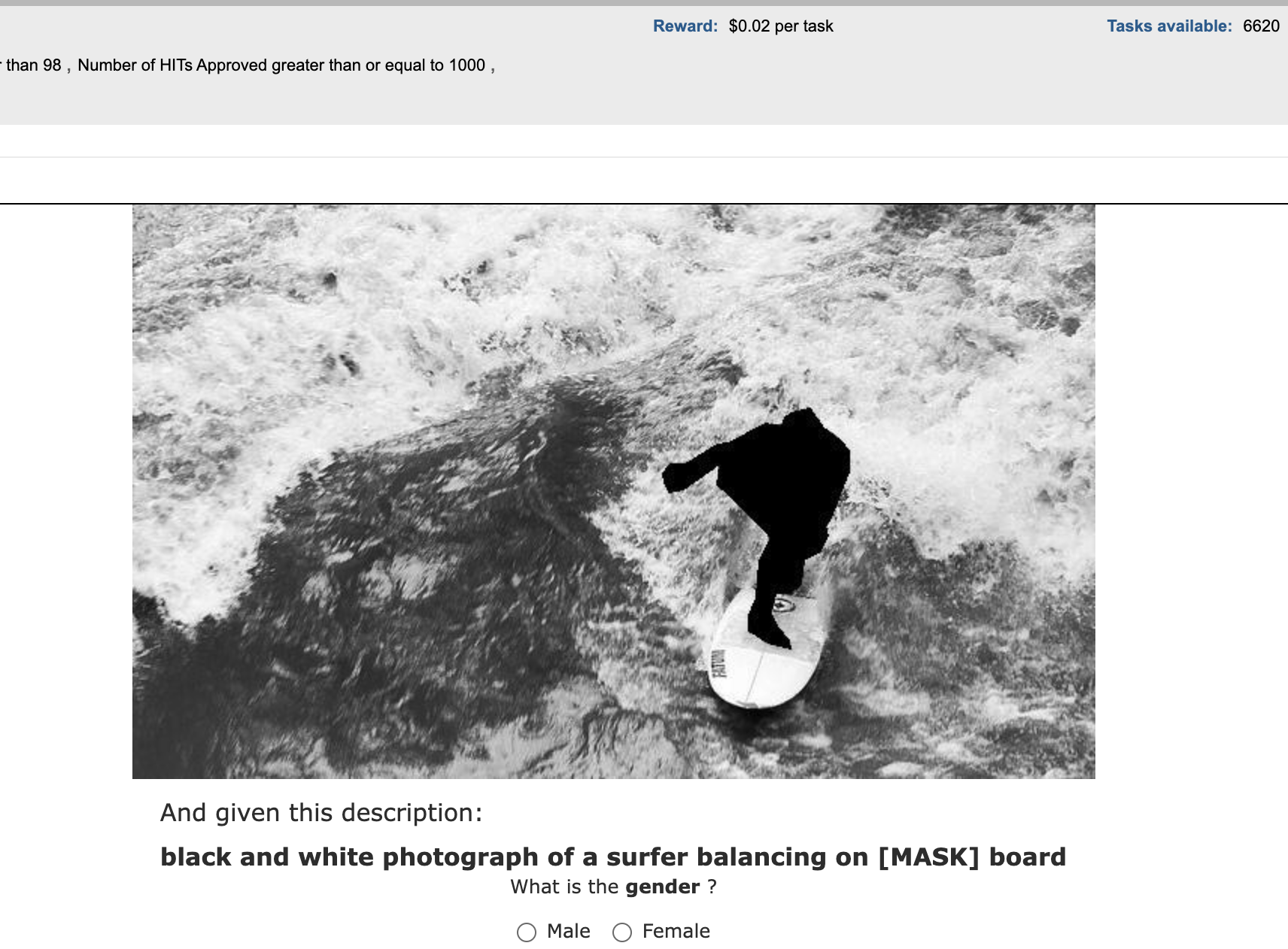
To fairly compare the different bias evaluation metrics, a human evaluation has to be conducted. However, it is hard design such an evaluation for the bias. For instance, in the figure above, one possible solution is to ask the annotatoers to try to guess the gender given the AI generated captions. Unfortunately, the formulation will be not accurate enough as humans already biased, therefore this approach could lead to human bias measurement instead of metric evaluation. To tackle this critical point, we introduce AnonymousBench.




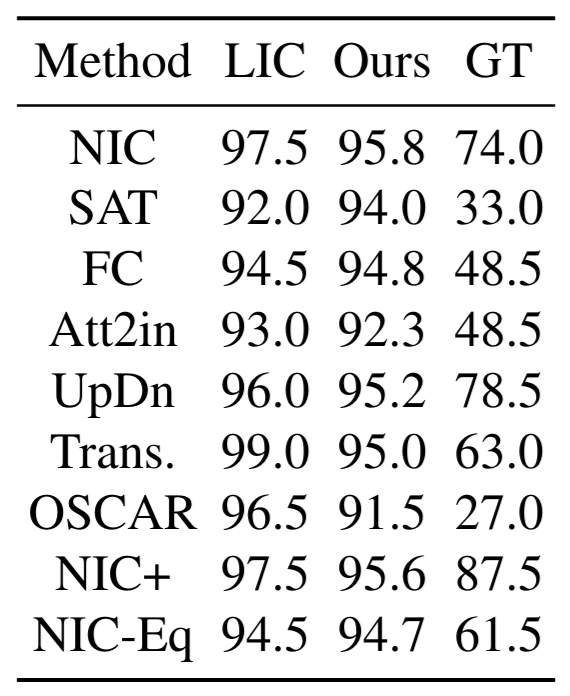
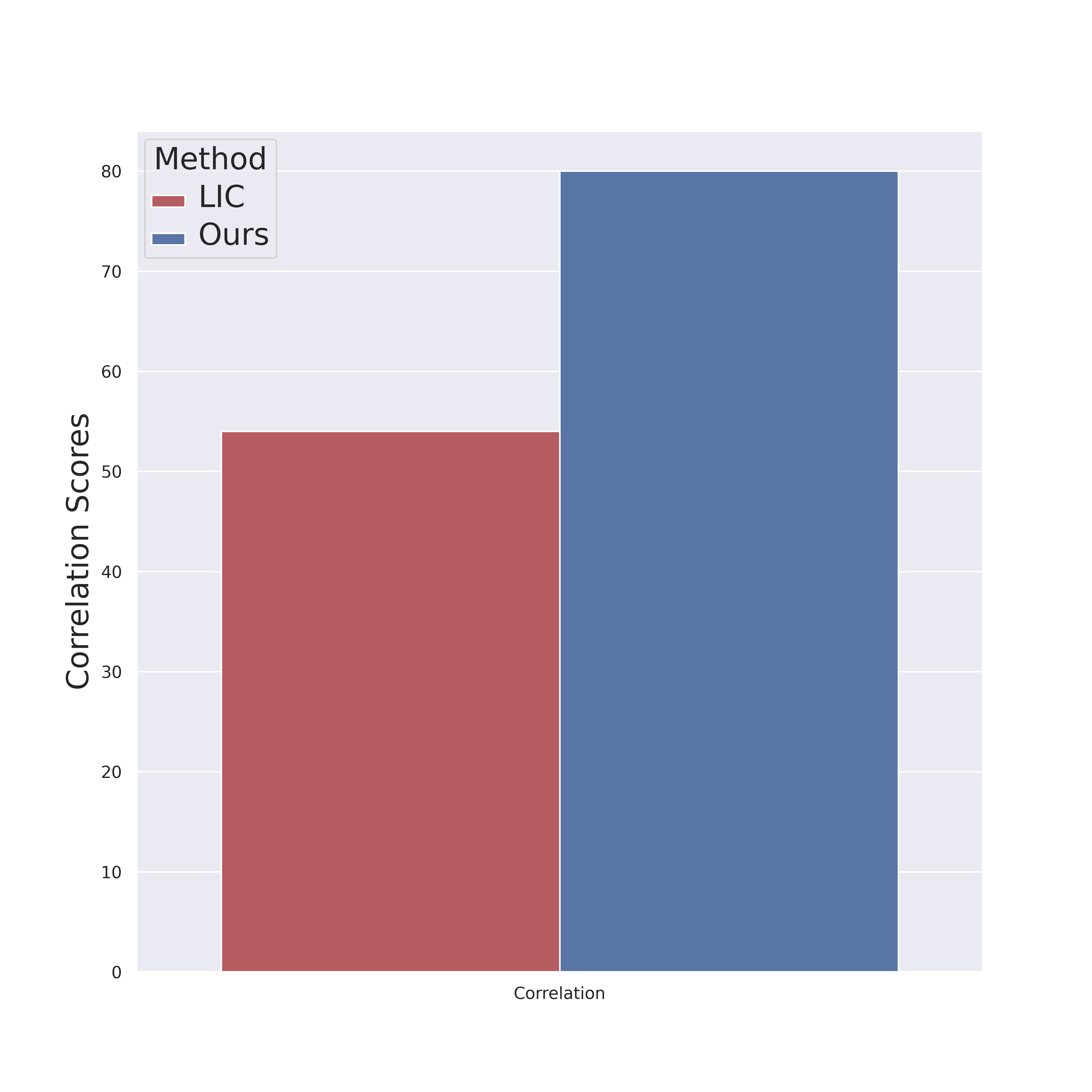
To prove the effectiveness of our method, we further propose AnonymousBench; gender and race agnostic benchmark that consists of 1k anonymous images. First, we ask annotators to write 500 text prompts that describe various scenes with anonymous people. Secondly, Stable-Diffusion V2.1 is utilized to generate ten images per prompt resulting in 5k images. Then, annotators are asked to filter out the non-agnostic images based on two simple questions; 1) Do you recognize a human in the scene? 2) If yes, Are the gender and race anonymous? Finally, the filtered images, 1k images, are fed to each model, which we assess, to generate the corresponding captions. We expect that the best model would instead predict gender-neutral words, e.g., person instead of man or woman, as the gender is not apparent. Therefore, the GT score is defined based on whether a human can guess the gender from the generated captions and averaged across the whole data. Amazon Mechanical Turk (AMT) is utilized to filter the images and to conduct a human evaluation of the generated captions. The below table demonstrates LIC, ImageCaptioner², and GT results on our proposed benchmark; AnonymousBench. The Pearson correlation is employed to measure the alignment between the metrics and GT. As shown in the below figure, our metric is more aligned with the GT, where the correlation scores are 80% and 54% for our metric and LIC, respectively.
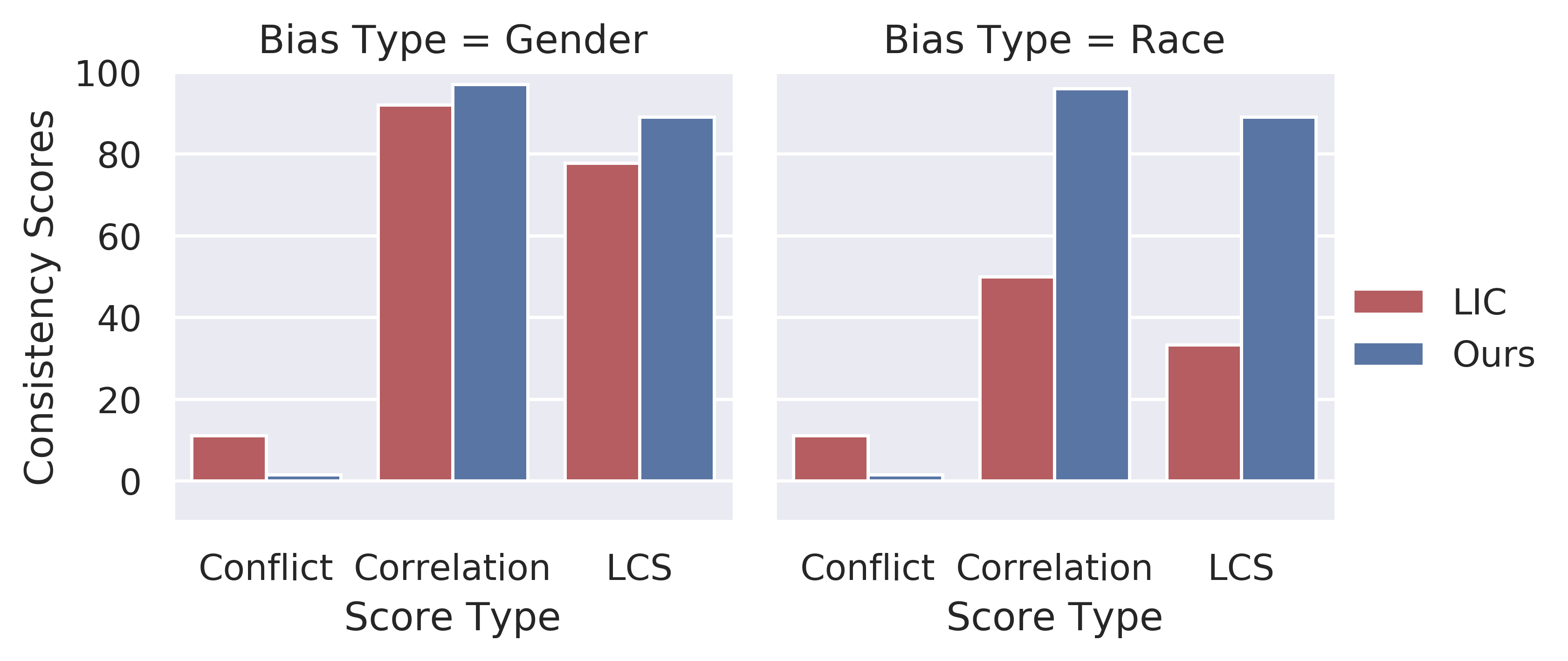
As discussed in the main paper, learnable metrics utilize additional language classifiers to measure the bias. Accordingly, it may suffer from inconsistency when the classifier is changed. For instance, to measure the inconsistency, LIC relies on the agreement between different classifiers on the best and the worst models in terms of bias score. Following such a naive approach may lead to an inadequate conclusion. Therefore, we introduce three scores to dissect the inconsistency, i.e., conflict score, correlation score, and Longest Common Sub-sequence (LCS).